AUTOMATION PSYCHOLOGY
Automation
Noun: Any sensing, detection, information processing, decision making or control action that could be performed by humans but is actually performed by machine.
Verb: The designing, engineering, implementation process resulting in the above.
Verb: The designing, engineering, implementation process resulting in the above.
Types of Automation
Types and Levels of Automation
A model to describe automation.
Parasuraman, R., Sheridan, T.B. & Wickens, C.D. (2000). A model for Types and Levels of Human Interaction with Automation. IEEE Transactions on Systems, Man, and Cybernetics -- Part A: Systems and Humans, 30 (3), 286-297.
Parasuraman, R., Sheridan, T.B. & Wickens, C.D. (2000). A model for Types and Levels of Human Interaction with Automation. IEEE Transactions on Systems, Man, and Cybernetics -- Part A: Systems and Humans, 30 (3), 286-297.
Types
What is being automated? (Following simple four-stage model of human information processing.)
- Information acquisition, selection, filtering. (Sensory processing.)
- Information integration. (Perception, working memory.)
- Action selection and choice. (Decision making.)
- Control and action execution. (Response selection.)
Levels
Levels of automation of decision and action selection.
10. The computer decides everything, acts autonomously, ignoring the human.
9. ... informs the human only if it decides to.
8. ... informs the human only if asked for.
7. ... executes automatically, then necessarily informs the human.
6. ... allows the human a restricted time to veto before automatic execution.
5. ... executes its suggestion if the human approves.
4. ... suggests one alternative.
3. ... narrows the selection down to a few.
2. ... offers a complete set of decision/action alternatives.
1. ... offers no assistance: human must take all decisions and actions.
10. The computer decides everything, acts autonomously, ignoring the human.
9. ... informs the human only if it decides to.
8. ... informs the human only if asked for.
7. ... executes automatically, then necessarily informs the human.
6. ... allows the human a restricted time to veto before automatic execution.
5. ... executes its suggestion if the human approves.
4. ... suggests one alternative.
3. ... narrows the selection down to a few.
2. ... offers a complete set of decision/action alternatives.
1. ... offers no assistance: human must take all decisions and actions.
Supervisory Control
Delegating the active executive tasks to automation leaves the human operator as passive, out-of-the-loop supervisor, with risk of complacency as a major concern.
Operator tasks
- Planning what needs to be done, based on a model of the physical system to be controlled, objectives and possibilities.
- Teaching the automation, i.e. deciding on a desired control action and communicating the necessary commands to the automation.
- Monitoring, i.e. allocating attention among the appropriate displays or other sources of information about task progress and estimate the current state of the system, to maintain situation awareness.
- Intervening, i.e. reprogramming or taking over manual control from the automation in case of a diagnosed abnormality of sufficient magnitude.
- Learning from knowledge of the results, like planning, is an out-of-the-loop human function and feeds back into planning the next phase of supervision.
Monitoring strategy
Moray, N. & Inagaki, T. (2000) Attention and Complacency. Theoretical Issues in Ergonomics Science, 1 (4), 354-365.
Complacency should measure defective monitoring, not the number of missed signals, as these could be caused by other variables such as system design, training, workload, and monitoring strategy.
A monitoring strategy is a plan of action to most effectively sample multiple sources, and is influenced by system knowledge (reliability, range limits, possible consequences) and the task at hand. It is not always possible to catch all signals; an optimal strategy may therefore still result in misses. "Complacency" may in fact be part of an appropriate monitoring strategy as highly reliable processes, or currently high-divergence meters, require less sampling.
As a reference to measure complacency, an optimal monitoring strategy should be defined. On a scale from scepticism (under-trust, over-sampling) to complacency (over-trust, under-sampling), eutactic behaviour would hold the middle, where optimal monitoring occurs with the right amount of trust and sampling. Experimentally, this means monitoring strategy (e.g. through eye-tracking) needs to be investigated, not (just) detection rate.
Complacency should measure defective monitoring, not the number of missed signals, as these could be caused by other variables such as system design, training, workload, and monitoring strategy.
A monitoring strategy is a plan of action to most effectively sample multiple sources, and is influenced by system knowledge (reliability, range limits, possible consequences) and the task at hand. It is not always possible to catch all signals; an optimal strategy may therefore still result in misses. "Complacency" may in fact be part of an appropriate monitoring strategy as highly reliable processes, or currently high-divergence meters, require less sampling.
As a reference to measure complacency, an optimal monitoring strategy should be defined. On a scale from scepticism (under-trust, over-sampling) to complacency (over-trust, under-sampling), eutactic behaviour would hold the middle, where optimal monitoring occurs with the right amount of trust and sampling. Experimentally, this means monitoring strategy (e.g. through eye-tracking) needs to be investigated, not (just) detection rate.
Decision Support Systems
Decision support systems are a type of interactive systems that are generally automated up to the third stage (action selection and choice), but leave the execution to the operator. The operator is assisted his choice of action.
Alarms and Warnings
Meyer, J. (2004). Conceptual Issues in the Study of Dynamic Hazard Warnings. Human Factors, 46 (2), 196-204.
Dynamic warnings are sensor-based signaling systems, that present, at any moment in time, one of two or more messages (including inactivity) based on input from sensors, people, or computational devices. Some messages may alert the user about a situation requiring closer monitoring or intervention.
Dynamic warnings are sensor-based signaling systems, that present, at any moment in time, one of two or more messages (including inactivity) based on input from sensors, people, or computational devices. Some messages may alert the user about a situation requiring closer monitoring or intervention.
Compliance and reliance
In response to a warning, compliance denotes the response when an operator acts as the warning implies even when it is false (error of commision), whereas reliance denotes not responding when the warning does not explicitly implies action, even when action is required (error of omission). Studies suggest that these are independent constructs, influenced separately by various factors. For example, reliance may decrease with experience while compliance remains unchanged. At least one study challenges that (see below).
Rational response
Expectancy-Value Theory can be used to describe the rational response, which would be to maximise expected value. Where a failure is either present (F) or not present (N), an operator can act as if it is present (f) or not act (n). The operator should act when EVf > EVn. This may depend on the probability of F. A threshold probability pF* can then be calculated, above which the operator should respond with f. Warning systems effect a change in pF: The probability of a failure is supposedly greater when the warning is given (pF|W). The operator should act when pF|W > pF*, but a system may not be that well-calibrated.
According to EV analysis, the correct response does not depend on the outcome, but on the a priori computation. Acting was the correct response when the connected EV was higher than that of not acting, even when the action led to negative effects. Performing many unnecessary actions (i.e. commission errors) may be appropriate when the cost of missing a necessary action is high. Errors of omission and commission are therefore not necessarily incorrect actions.
According to EV analysis, the correct response does not depend on the outcome, but on the a priori computation. Acting was the correct response when the connected EV was higher than that of not acting, even when the action led to negative effects. Performing many unnecessary actions (i.e. commission errors) may be appropriate when the cost of missing a necessary action is high. Errors of omission and commission are therefore not necessarily incorrect actions.
Determinants of response
Assuming a multitask environment and an experienced operator (who has noticed and understood the warning, and samples multiple sources of information), the following factors influence response behaviour.

Note the various interaction effects (e.g. operator factors and task demands) and closed-loop dynamics (e.g. learning effects).
- Normative factors: Characteristics of the situation.
- Situational factors: Related to properties of the situation in which a warning is used, e.g. probability of failures, payoff structure.
- Diagnostic factors: Related to the warning system (e.g. SDT sensitivity, conditional probabilities) and the available additional information.
- Task factors: Related to the characteristics of the task during which a warning is encountered.
- Task structure factors: E.g. the number of different variables/systems that need to be controlled, the presence of other people.
- Interface factors: Related to the way the task-relevant information is displayed and the display/control design, e.g. signal urgency (flashing, coloured).
- Operator factors: Variables that characterise the individual operator in the particular situation.
- General operator factors: E.g. abilities, training, skills, risk-taking tendency, strategies.
- System-specific operator factors: E.g. the operator's trust in the system, knowledge of the system.
Note the various interaction effects (e.g. operator factors and task demands) and closed-loop dynamics (e.g. learning effects).
Orientation
Reliance-oriented automation indicates that the system is operating normally. The operator needs to act when the automation fails to provide this indication (implicit indicator of the need to act).
Compliance-oriented automation indicates an abnormal situation, and the operator needs to act in response to this indicator (explicit indicator of the need to act).
Compliance-oriented automation indicates an abnormal situation, and the operator needs to act in response to this indicator (explicit indicator of the need to act).
False alarms
False alarms or false positives are signals given off that do not reflect the true state of the world as intended.
Traditional false alarm
A state is being signalled that is not actually there.
Nuisance alarm
The alarm is being given in the wrong context or caused by irrelevant factors.
Inopportune alarm
The alarm is being given at an inopportune point in time, usually too early, leaving the operator unable to correctly interpret it.
Cry-wolf effect
Too many false alarms lead operators to ignore these alarms, increasing the chance of missing a true positive, or when they do respond, respond slower.
Countermeasures
Technology-based countermeasures include likelihood alarm displays and optimal calibration.
Operator-based strategies include training.
Task-based strategies include workload reduction.
Operator-based strategies include training.
Task-based strategies include workload reduction.
Ironies of Automation
Bainbridge, L. (1983). Ironies of Automation. Automatica, 19 (6), 775-779.
Human error
Automation is implemented to prevent human error by replacing the human; however, (human) design error is a major source of automation problems. A human supervisor remains necessary to make sure the automation itself does not commit any errors.
Operator tasks
A human operator remains necessary to see to those tasks which could not be automated, potentially giving him an arbitrary list of unconnected tasks. Additionally, his intervention is required when the automation fails to manage its tasks, i.e. in particularly critical situations, meaning the "error-prone" human must take over in particularly "error-prone" situations.
Potential Problems with Automation
Vigilance
Humans are notoriously bad at vigilant monitoring, a task that increases in relevance with increasing automation.
Deskilling
Due to the operator's inactivity as perceiver, decision maker, actor, and controller, these skills that are no longer used may be lost -- but are no less required in critical situations.
Workload
Automation is intended to reduce workload, yet it does not reduce, but change the tasks of the operator, and may in fact disproportionally spread workload over situations.
Clumsy automation
Automation that reduces workload in situations with already low workload, and increases workload in already highly demanding situations.
Situation Awareness
"The perception of elements in the environment within a volume of time and space (level 1), the comprehension of their meaning (level 2), and the projection of their status in the near future (level 3)".
In connection with automation, following issues can be found at these levels.
Level 1
Levels 2 and 3
Additionally, ten "demons" of SA have been formulated. Lack of situation awareness can lead to automation surprises and mode errors.
In connection with automation, following issues can be found at these levels.
Level 1
- Lacking supervision, e.g. caused by overtrust or vigilance problems.
- Changed feedback channels. Automation can change and/or reduce the flow of information to the operator.
- Lacking system transparency. The operator may not be sufficiently informed about what the automation is currently doing.
Levels 2 and 3
- Complexity. Complex systems are difficult to understand, leading to an
- incorrect mental model, leaving the operator unable to properly understand the automation even when it is working properly.
Additionally, ten "demons" of SA have been formulated. Lack of situation awareness can lead to automation surprises and mode errors.
Demons of Situation Awareness
- Attentional Tunneling: SA is particularly important in complex environments, where shared attention is required. Due to limited attentional resources, selective attention is employed. SA is largely dependent on the strategy of selective attentional sampling.
- Working memory limitations: Especially problematic for novices who cannot yet "chunk" situations and system states.
- Workload, Anxiety, Fatigue and Other factors (WAFOS) further limit available resources and lead to more troublesome information acquisition (e.g. attentional tunneling) and generally less well structured, more error-prone information processing, leading e.g. to premature closure, "jumping to conclusions".
- Information overload as caused by the increase of information, the way it is presented, and speed with which it is presented. "It's not a problem of volume, but of bandwidth!"
- Misplaced salience. Saliently presented elements, while advantageous in some cases, can be distracting in others.
- Complexity creep and feature escalation, the continuous addition of functionality and complexity.
- Incorrect mental model can be particularly problematic, as persons do not realise that their mental model is faulty.
- Out Of The Loop Unfamiliarity (OOTLUF) as characterised by complacency and deskilling.
Automation surprises
When the automation does not act or respond as was expected or as can be understood.
Mode errors
The operator uses the system as if it was in a different mode, and is therefore surprised by/does not understand the resulting feedback.
Measuring Situation Awareness
There are a number of ways in which one might attempt to measure SA. However, many of these cannot measure SA specifically. Eye-tracking, for example, indicates what information has been looked at, but it not what information has been seen. EEG, then, allows registration of perception and processing, but leaves out the critical element of correct interpretation. Global performance measures only measure the result of a long cognitive process, providing little information about what exactly caused this performance -- particularly, poor performance can be the result of any number of measures that are not SA-related. External task measures (e.g. changing a specific element on the display and timing how long it takes to be noticed) may better differentiate this, but is highly intrusive and assumes that the operator will act in certain way which he very likely will not. Embedded task measures are performance measures on subtasks which may provide inferences about SA related to that task, but this would not measure when for example improvement on this subtask leads to a decrement on another, and it may be difficult to select relevant tasks. A number of subjective techniques have been developed. An observer (either separately or, unknown by the subject, as a confederate), especially a trained one, may have good situational knowledge but cannot know what exactly the operator's concept of the situation is. For the Subjective Workload Dominance metric (SWORD), subjects make pair-wise comparative ratings of competing design concepts along a continuum that expresses the degree to which one concept entails less workload than the other, resulting in a linear ordering of the design conceps. The exact role of SA in this however, is unclear. Specifically for SA measurement, the Situation Awareness Rating Technique (SART) is a subjective rating scale that considers the operators' workload in addition to their perceived undertanding of the situation. However, someone who is aware of what he does not know (and with that, may be said to have better understanding) may therefore rate his understanding lower than someone who knows less but is not aware of it.
The Situation Awareness Global Assessment Technique (SAGAT) is specifically designed to objectively measure SA across all three levels. To this end, a simulation is frozen, all displays blanked out, and a number of questions are asked regarding the state of the situation before the freeze. These questions are designed with the operators' goals in mind, working down past the decisions and judgements required to achieve those goals, to what needs to be known, understood, and foreseen. The questions need to be posed in a cognitively compatible manner, preventing the operator from having to perform any transformations of the information which may influence the answer, or may cause him to reconstruct, rather than recall, the information.
The Situation Awareness Global Assessment Technique (SAGAT) is specifically designed to objectively measure SA across all three levels. To this end, a simulation is frozen, all displays blanked out, and a number of questions are asked regarding the state of the situation before the freeze. These questions are designed with the operators' goals in mind, working down past the decisions and judgements required to achieve those goals, to what needs to be known, understood, and foreseen. The questions need to be posed in a cognitively compatible manner, preventing the operator from having to perform any transformations of the information which may influence the answer, or may cause him to reconstruct, rather than recall, the information.
Trust
Trust is influenced by the system's perceived reliability, the human's predisposition towards technology, his self-efficacy and many other aspects (see dynamic model). Inhowfar the operator's trust is appropriate, is referred to as its calibration.
Calibration
Ideally, the operator's trust is well-calibrated, i.e. in direct relation to the automation's actual reliability. When this is not the case, we speak of mistrust. Two aspects of calibration:
- Resolution refers to how precisely a judgement of trust differentiates levels of automation capability. With low resolution, large changes in automation capability are reflected in small changes in trust.
- Specificity refers to the degree to which trust is associated with a particular component or aspect of the automation. Functional specificity: The differentiation of functions, subfunctions and modes. Low functional specificity means trust is based on the system as a whole. Temporal specificity describes changes in trust over time. High temporal specificity means that trust reflects moment-to-moment changes.
Dynamic Model
Based on Lee, J.D. & See, K.A. (2004). Trust in Automation: Designing for Appropriate Reliance. Human Factors, 46 (1), 50-80.

Some notes:
Some notes:
- Context
- Individual: Predisposition to trust as a general personality trait, e.g. as operationalised through the Interpersonal Trust Scale (Rotter, 1980) or the Complacency Scale (Singh, Molloy & Parasuraman, 1993). A higher general level of trust is not correlated with gullibility; is positively correlated with correct assessment of trustability of others.
- Individual: Trust as dynamic attitude evolves with time during a relationship based on experience.
- Organisational: Represents interactions between people, e.g. when informing one another about others' trustworthiness.
- Cultural: The set of social norms and expectations based on shared education and experience influences trust. Collectivistic (as compared to individualistic) cultures have a lower general level of trust, as "trust" as a concept is less needed due to clear division roles.
- Environmental: Specific situational factors can influence the automation's capability, e.g. when a situation occurs for which the automation was not designed.
- Trust is ultimately an affective response, but is influenced by analytic and analogical considerations (though not as much as vice versa).
- Reliance: Having formed an intention to rely on the automation based on how much it is trusted, while for example also taking into consideration workload, contextual factors such as time constraints may still prevent the automation from actually be relied upon.
- Automation
- Information about the automation can be described along two dimensions.
Attributional abstraction refers to attributions on which trust can be based. Performance refers to what the automation does: Current and historical operation of the automation, or competence as demonstrated by its ability to achieve the operator's goals. Process information describes how the automation operatates: The degree to which the algorithms are appropriate and able. Purpose describes why the automation was developed.
The level of detail refers to the functional specificity of the information. - The display is often the only way to communicate this information. A number of aspects of display design can influence trust.
Structure and organisation are important for all three paths of trust evolution.
For the analytic and analogic aspects specifically, the exact content need to be considered, as well as its amount: Too much information may take too long to interpret. This needs to be weighed against aspects of specificity.
Affectively, good design (aesthetics, use of colour etc.) can increase trust -- even if this is inappropriate. Other things known to increase trust are a "personality" of the automation that is compatible to the operator's (as e.g. communicated by human-like voice output), the display's pictorial realism, its concreteness, and its "real world feel" (being more than merely virtual).
- Information about the automation can be described along two dimensions.
- Closed-loop dynamics: The output of each process influences the input of the other. For example, a low level of initial trust can mean that the automation is not used at all, whereas a higher level of initial trust can lead to subsequent experience and further increased trust. Reliance is an important mediator.
Mistrust
When trust is not well-calibrated, either too high or too low.
Distrust
The operator has less trust in the automation than is warranted. Could lead to disuse, using the system less than is warranted. Even rare failures, especially ununderstandable failures, can lead to a reduction in perceived reliability, and with that, to distrust and disuse.
Overtrust
The operator has more trust in the automation than is warranted. Long experience with often highly reliable systems can lead to too high an estimation of its reliability. Overtrust can lead to misuse, or specifically, complacency and automation bias.
Complacency
No one clear definition; e.g. "(self-)satisfaction, little suspicion based on an unjustified assumption of satisfactory system state leading to non-vigilance." Lacking supervision of automated systems leads to
- detection issues: Errors will be overseen, which may in turn increase complacency as the amount of errors wrongfully appears to be low.
- loss of situation awareness, as the operator is no longer sufficiently vigilant to keep track of all processes.
Automation bias
"Automated cues as heuristic replacement for more vigilant and complete information search processing": The operator trusts that the automation will always indicate critical situations and no longer surveys the relevant information himself (error of omission; operator does not take action because he is not explicitly informed), and/or assumes the automated indications are correct and follows them without verifying them or while ignoring contradictory information (error of commission; taking action on the basis of a false cue). Particularly relevant to decision support systems.
Assimilation bias
Interpreting other indicators, insofar they are processed, as being more consistent with the automated information than they really are.
Discounting bias
Discounting information inconsistent with the automated information.
Confirmation bias
Overattending to, or seeking out, consistent information and ignoring other data, or processing new information in a manner that confirms one's preexisting beliefs.
Using Automation
Use
Whether or not automation is used, depends on the operator's general attitude towards technology, his trust in the automation, his current workload, the required cognitive overhead, his self-efficacy and situational factors.
Misuse
Using the system more than is warranted. This result from overtrust can lead to e.g. erroneous decision making, use of heuristics, premature closure, automation bias and complacency.
Disuse
Using the system less than is warranted. This result from distrust is caused e.g. by general mistrusting the automation's capabilities, general mistrust of (new) technology and false alarms.
Abuse
Any inappropriate use of the system, or inappropriate implementation of automation as for example caused by technical or economical factors.
Selected Literature and Empirical Findings
General
MABA-MABA or Abracadabra?
Dekker, S.W.A. & Woods, D.D. (2002). MABA-MABA or Abracadabra? Progress on Human-Automation Co-ordination. Cognition, Technology & Work, 4, 240-244.
Dekker and Woods criticise MABA-MABA lists and the TALOA model, saying they lead automation developers to believe that these provide simple answers to the question of what to automate. The "simple answers" provided by these tools, are misleading because of the following.
Engineers need to be aware that it is not so, that new technology simply changes the role of the operator who then needs to adapt. New technology changes the entire situation, leading people to adapt the technology again, and so forth. Engineers need to accept that their technology transforms the workplace and need to learn from these effects.
To this end, the authors suggest that automation should be conceived of as a "teamplayer", capitalising on human strengths such as pattern recognition and prediction, and making communication (programming) easy.
Dekker and Woods criticise MABA-MABA lists and the TALOA model, saying they lead automation developers to believe that these provide simple answers to the question of what to automate. The "simple answers" provided by these tools, are misleading because of the following.
- Arbitrary granularity. The four-stage division of TALOA follows only one of many possible models, all of which are probably incorrect.
- Technology bias through misleading metaphors. When it's not a model of information processing that determines the categories, the technology itself often does so, as e.g. the original MABA-MABA lists distinguish aspects as "information capacity" and "computation". These are technology-centred aspects, biased against humans and leaving out typically human abilities such as anticipation, inference, collaboration etc.
- Ignoring qualitative effects. The "substitution myth" assumes automation can simply replace humans and that's that. However, capitalising on some strength of automation does not replace a human weakness. It creates new human strengths and weaknesses as it qualitatively changes the human's tasks and environment.
Engineers need to be aware that it is not so, that new technology simply changes the role of the operator who then needs to adapt. New technology changes the entire situation, leading people to adapt the technology again, and so forth. Engineers need to accept that their technology transforms the workplace and need to learn from these effects.
To this end, the authors suggest that automation should be conceived of as a "teamplayer", capitalising on human strengths such as pattern recognition and prediction, and making communication (programming) easy.
Human factors and folk models
Dekker, S. & Hollnagel, E. (2004). Human factors and folk models. Cognition, Technology & Work, 6, 79-86.
The authors argue that human factors constructs such as complacency show characteristics of folk models, namely
The authors argue that human factors constructs such as complacency show characteristics of folk models, namely
- Explanation by substitution: Substituting one label for another rather than decomposing a large construct into more measurable specifics. For example, none of the definitions of complacency actually explain it, but "define" it by substituting one label for another (complacency is, for example, "self-satisfaction", "overconfidence", "contentment" etc.), making claims of complacency as causal factor immune to critique. None of the definitions explain how complacency produces vigilance decrements or leads to a loss of SA. In fact, replacing an arbitrary set of factors by the umbrella term "complacency" represents a significant loss of actual information and the inverse of scientific progress. A better alternative would be to use better-known and preferably measurable concepts.
- Immunity against falsification, due to being underspecified and open to interpretation. For example, if the question "where are we headed?" between pilots is interpreted as loss of SA, this claim is immune against falsification. Current theories of SA are not sufficiently articulated to explain why this question should or should not represent a loss of SA.
- Overgeneralisations. Overgeneralisations take narrow laboratory findings and apply them uncritically to any broad situation where behavioural particulars bear some resemblance to the phenomenon that was investigated under controlled circumstances. The lack of precision of folk models and their inability to be falsified contribute to this.
Situation Awareness, Mental Workload, and Trust in Automation
Parasuraman, R., Sheridan, T.B. & Wickens, C.D. (2008). Situation Awareness, Mental Workload, and Trust in Automation: Viable, Empirically Supported Cognitive Engineering Constructs. Journal of Cognitive Engineering and Decision Making, 2 (2), 140-160.
The authors counter the arguments in the above two papers by DWH.
Abracadabra
DWH are said to be uninformed of current literature, dominant attitudes in the scientific community and engineering processes. TALOA was never intended as a method, and current "MABA" lists do include the typical human strengths that DWH missed in Fitts' original, known to be deprecated lists. There was no advocacy of substitution, only guidance in what to consider.
Folk models
In general, DWH are accused of a blame-by-association approach (misapplication of theories by some does not mean the theories themselves are incorrect) and of using strawman arguments.
The authors counter the arguments in the above two papers by DWH.
Abracadabra
DWH are said to be uninformed of current literature, dominant attitudes in the scientific community and engineering processes. TALOA was never intended as a method, and current "MABA" lists do include the typical human strengths that DWH missed in Fitts' original, known to be deprecated lists. There was no advocacy of substitution, only guidance in what to consider.
Folk models
- Situation awareness is diagnostic of different humen operator states and therefore prescriptive as to different remedies. It represents a continuous diagnosis of the state of a dynamic world, and has an objective truth against which its accuracy can be measured (namely, the actual state of that world).
In focusing on performance measures, DWH fail to note the distinction between psychological constructs and performance. Different displays, automation levels and procedures are required for supporting performance than for supporting SA. SA becomes particularly relevant when things go wrong, i.e. fall outside of normal performance.
The authors note that conclusions regarding SA measurement and its implications have been supported by strong empirical research. - Mental workload. Workload, like SA, also generates specific diagnoses with prescriptive remedies for overload and underload. The distinction between performance is again important: Two operators may have the same performance, but markedly different workload (e.g. as available residual attention). Workload has proven relevant to understanding the relation between objective task load and task strategies. In driving, high workload is a good predictor for a future performance drop, not predictable by current performance measures.
The concept of mental workload has been supported by strong science. - Trust in automation and complacency. A large body of research has clearly established the importance of trust in the human use of automation. The existence of various definitions for complacency is not a valid argument. Empirically, numerous studies indicate that operator monitoring in systems with imperfect automation can be poor. These findings are based on objective measures.
In general, DWH are accused of a blame-by-association approach (misapplication of theories by some does not mean the theories themselves are incorrect) and of using strawman arguments.
Situation Awareness
Measurement of Situation Awareness
Endsley , M.R. (1995). Measurement of Situation Awareness in Dynamic Systems. Human Factors, 37 (1), 65-84.
Two experiments address the question whether or not SAGAT is a valid measure -- whether or not it indeed measures what it is supposed to measure. Two reasons why it may not are mentioned.
The first study deals with the memory issues by, in multiple trials, administering a full battery of SAGAT in random order. Due to the random order, the time at which each question was asked after the freeze varied up to six minutes. Endsley found that the majority of absolute error scores were within acceptable limits of error (meaning information can indeed be reported), and that no effect of time on error score was found (there is no sign of short-term memory decay).
To address the technique's potential intrusiveness, during a similar study, the amount (0-3) and duration (half, one, two minutes) was varied across trials. No performance difference was registered in any of the conditions.
A number of issues related to these experiments can be identified.
Two experiments address the question whether or not SAGAT is a valid measure -- whether or not it indeed measures what it is supposed to measure. Two reasons why it may not are mentioned.
- Memory issues: If the information is processed in a highly automated fashion, it may not enter into consciousness. If it does, short-term memory span may prevent it from being reported after the simulation has frozen. Even if it even enters term memory, recall issues may still prevent it from being recalled.
- Intrusiveness of the freeze may alter the operators' behaviour.
The first study deals with the memory issues by, in multiple trials, administering a full battery of SAGAT in random order. Due to the random order, the time at which each question was asked after the freeze varied up to six minutes. Endsley found that the majority of absolute error scores were within acceptable limits of error (meaning information can indeed be reported), and that no effect of time on error score was found (there is no sign of short-term memory decay).
To address the technique's potential intrusiveness, during a similar study, the amount (0-3) and duration (half, one, two minutes) was varied across trials. No performance difference was registered in any of the conditions.
A number of issues related to these experiments can be identified.
- A substantial amount of training missions in which SAGAT was also adminstered was flown before the actual trials. This is highly unusual: One does not usually train SAGAT at all. Data on the pilots' scores across missions is not available.
- The simulation only allowed ten out of twenty-six questions to be verified. These related to variables of high importance to flight. The fact that these can be reported, does not necessarily mean that other parameters can be as well. Additionally, these mostly related to Level 1 SA, meaning these findings cannot necessarily be extended towards other levels of SA.
- The subjects used in these studies were expert fighter pilots. The fact that experts are able to accurately report the requested information, does not necessarily mean that other subjects are able to do so as well.
- Endsley set out to investigate whether or not there was an effect, and claims to have proven a negative, which is fundamentally impossible.
Trust
The Dynamics of Trust
Lewandowsky, S., Mundy, M. & Tan, G.P.A. (2000). The Dynamics of Trust: Comparing Humans to Automation. Journal of Experimental Psychology: Applied, 6 (2), 104-123.
The authors developed the following tentative framework primarily describing the role of trust and self-confidence in an operator's decision to delegate tasks to an "auxiliary", usually automation.
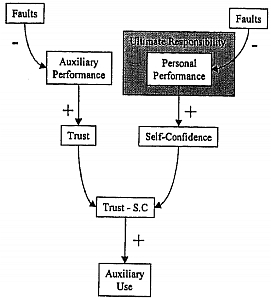
A trade-off between trust in the auxiliary and self-confidence is said to predict auxiliary use. In case of automation being the auxiliary aid, the ultimate responsibility is felt by the operator to be his and his alone. Especially because of that, faults affecting his performance are thought to affect his self-confidence. In case of the auxiliary being a human co-operator however, a perceived diffusion of responsibility is hypothesised to render self-confidence more resilient.
In a first experiment, subjects supervised a simulated pasteurisation process with (between subjects) either an automated auxiliary aid, or a thought-to-be human auxiliary aid. Subjects had the option to delegate the relevant task either to the auxiliary aid, or operate it manually. Within subjects, operating errors were introduced either (first) during manual control (manual fault) or during automated control (auxiliary fault). Switching to the other control would solve the problem.
Analysis focused on differences between human-human and human-automation cooperation situations regarding the following aspects.
In a second experiment, this unidentified variable was hypothesised to be the operator's presumed own trustworthiness as perceived by the auxiliary partner. They also introduced risk as an additional independent variable, in the form of process speed (higher speed leading to more performance loss in case of errors).
The authors developed the following tentative framework primarily describing the role of trust and self-confidence in an operator's decision to delegate tasks to an "auxiliary", usually automation.
A trade-off between trust in the auxiliary and self-confidence is said to predict auxiliary use. In case of automation being the auxiliary aid, the ultimate responsibility is felt by the operator to be his and his alone. Especially because of that, faults affecting his performance are thought to affect his self-confidence. In case of the auxiliary being a human co-operator however, a perceived diffusion of responsibility is hypothesised to render self-confidence more resilient.
In a first experiment, subjects supervised a simulated pasteurisation process with (between subjects) either an automated auxiliary aid, or a thought-to-be human auxiliary aid. Subjects had the option to delegate the relevant task either to the auxiliary aid, or operate it manually. Within subjects, operating errors were introduced either (first) during manual control (manual fault) or during automated control (auxiliary fault). Switching to the other control would solve the problem.
Analysis focused on differences between human-human and human-automation cooperation situations regarding the following aspects.
- Performance. Faults did reduce performance, but the only significant difference was between pre-fault (where no faults were introduced) and auxiliary fault trials.
- Allocation strategy. Subjects developed strategies to combat the faults. In auxiliary fault trials, control was predominantely allocated manually, and vice versa. Additionally, it appeared (not enough subjects for significance) that the subjects' perception of automation is more volatile, indicated by automation trials leading to more "extreme" allocation strategies (higher percentage of either manual or automation control).
- Subjective ratings and auxiliary use. In the automation condition, periods of manual faults were associated with low self-confidence and high trust, whereas automation faults engendered low trust but high self-confidence. In the human condition however, self-confidence was found to be fairly stable across all trials. Trust minus self-confidence appeared to indeed be a good predictor for auxiliary use, but less so in the human condition, hinting at the relevance of another, yes unidentified variable.
In a second experiment, this unidentified variable was hypothesised to be the operator's presumed own trustworthiness as perceived by the auxiliary partner. They also introduced risk as an additional independent variable, in the form of process speed (higher speed leading to more performance loss in case of errors).
- Performance. Again, performance declined when faults were introduced. An interaction effect, possibly due to learning as the here-relevant order was not randomised, was seen in auxiliary faults impairing performance more in slow conditions than in fast ones. No such effect was seen in the human condition.
- Allocation strategy. Results were as above in low-speed conditions. This pattern was more accentuated in high-speed conditions: No more than one subject continued to favour using the auxiliary after it developed faults. There was no hint of any differences between auxiliary type conditions.
- Subjective ratings and auxiliary use. Independent of auxiliary type condition, auxiliary faults led to lower trust and higher self-confidence, and manual faults led to higher trust and lower self-confidence. The failure to replicate self-confidence resilience in human conditions might have been due to the faults appearing more extreme in this second experiment, causing self-confidence to decline regardless of auxiliary partner. Trust minus self-confidence again was a good predictor of auxiliary use, again a bit better in the automation condition. Presumed trustworthiness declined in manual fault trials. In human conditions, subjects were likely to delegate tasks to their partner when their presumed trustworthiness was low, and vice versa. Presumed trustworthiness played no role however, in predicting auxiliary use in the automation condition.
Monitoring, Complacency
Performance Consequences of Automation-Induced "Complacency"
Parasuraman, R., Molloy, R. & Singh, I.L. (1993). Performance Consequences of Automation-Induced "Complacency". International Journal of Aviation Psychology, 3 (1), 1-23.
Langer's (1989) concept of premature cognitive commitment describes an attitude that is formed upon a person's first encounter with a system, and reinforced when the device is re-encountered in the same way. Variability in automation reliability then, may interfere with producing this type of attitude, and with that, reduce complacency.
The authors examined the effect of reliability variations on operator detection of automation failures using a flight simulation that included manual tracking and fuel management, and an automated system-monitoring task. Four conditions: constantly low/high reliability, and variable reliability switching every ten minutes, starting low/high. Following hypotheses were investigated.
According to these findings, variable reliability may increase monitoring efficiency. In practice, this may be achieved by artifically introducing automation failures, which is risky, or by adaptive function allocation.
One might ask whether or not detection rate is an appropriate indicator for complacency and whether or not the chosen "high" (87,5%) and "low" (57,25%) reliability figures are acceptable.
Langer's (1989) concept of premature cognitive commitment describes an attitude that is formed upon a person's first encounter with a system, and reinforced when the device is re-encountered in the same way. Variability in automation reliability then, may interfere with producing this type of attitude, and with that, reduce complacency.
The authors examined the effect of reliability variations on operator detection of automation failures using a flight simulation that included manual tracking and fuel management, and an automated system-monitoring task. Four conditions: constantly low/high reliability, and variable reliability switching every ten minutes, starting low/high. Following hypotheses were investigated.
- Complacency is higher in constant reliability conditions: Confirmed, in that detection probability (assumed measure of complacency) was significantly higher in variable conditions.
- The higher the initial reliability, the higher the complacency: Not confirmed. No significant detection difference found within constant/variable conditions.
- An operator's trust in and reliance on automation weakens immediately after failure: Partly confirmed. Detection rate did improve after total automation failure in both conditions, but the constant reliability groups did not reach the same level as the variable reliability groups.
- he above predictions only hold in a multitask environment: Confirmed. A second experiment was conducted with the same training etc., but where only the previously automated system monitoring task was to be done. Detection rates were uniformly high across groups and sessions.
According to these findings, variable reliability may increase monitoring efficiency. In practice, this may be achieved by artifically introducing automation failures, which is risky, or by adaptive function allocation.
One might ask whether or not detection rate is an appropriate indicator for complacency and whether or not the chosen "high" (87,5%) and "low" (57,25%) reliability figures are acceptable.
Context-related Reliability
Bagheri, N. & Jamieson, G.A. (2004). The Impact of Context-related Reliability on Automation Failure Detection and Scanning Behaviour. Proceedings of the IEEE International Conference on Systems, Man and Cybernetics, 212-217.
Studies generally model automation failures as random, unpredictable events, and neglect to take into account, or inform the operators of, the conditions that might make automation failures more likely to happen. The authors investigated the effect of providing operators with information about the context-related nature of automation reliability.
The same procedure was used as in Parasuraman (1993) above. However, constant-high subjects were informed that automation would operate invariably "slightly under 100%", constant low "slightly more than 50%", and the same terms were used to describe the variable conditions with additional rationale of maintenance needing to happen ever 20 minutes improving reliability. The following effects were found on the dependent variables.
It appears increased understanding of the system can decrease complacency.
Studies generally model automation failures as random, unpredictable events, and neglect to take into account, or inform the operators of, the conditions that might make automation failures more likely to happen. The authors investigated the effect of providing operators with information about the context-related nature of automation reliability.
The same procedure was used as in Parasuraman (1993) above. However, constant-high subjects were informed that automation would operate invariably "slightly under 100%", constant low "slightly more than 50%", and the same terms were used to describe the variable conditions with additional rationale of maintenance needing to happen ever 20 minutes improving reliability. The following effects were found on the dependent variables.
- Performance measures. No significant difference was found between conditions: Detection rate was uniformly high, meaning an improvement compared to Parasuraman (1993). No significant differences were found between other performance measures. Providing information about the automation seemed to enhance participants' detection performance without affecting their performance on other tasks.
- Mean time between fixations. MTBF in constant high conditions was significantly smaller for those who received context information compared to those who did not. The information then, did seem to influence monitoring strategy.
- Subjective trust in the automation in context conditions appeared to be more stable even when failures are discovered.
It appears increased understanding of the system can decrease complacency.
Decision Support Systems
Misuse of automated decision aids
Bahner, J.E., Hüper, A. & Manzey, D. (2008). Misuse of automated decision aids: Complacency, automation bias and the impact of training experience. International Journal of Human-Computer Studies, 66, 688-699.
The authors investigated complacency effects towards decision aids in process control, and the role of prior experience with automation faults. In a simulated process of providing oxygen to astronauts, an automated system helped to diagnose errors. Initially, all participants are trained in manual control and error diagnosis, being explicitly told what information needs to be checked for which errors (normative model). Later, an automated diagnosistic aid is added, and all participants were told that failures may occur in this system, but only half of the participants actually experienced them during the training. In the experimental trials, after nine correct diagnoses, the system gave a faulty one. For two subsequent faults, the system broke down entirely and no diagnostic support was available. Results:
The study suggested a new way to measure complacency in comparing actual behaviour to a normative model. All subjects showed complacency to some extent, extending the significance of complacency to decision support systems. Subjects in the information group were more complacent and took less time to verify diagnoses, hinting at a role of time pressure. Participants who committed a commission error also showed particularly high levels of complacency.
The authors investigated complacency effects towards decision aids in process control, and the role of prior experience with automation faults. In a simulated process of providing oxygen to astronauts, an automated system helped to diagnose errors. Initially, all participants are trained in manual control and error diagnosis, being explicitly told what information needs to be checked for which errors (normative model). Later, an automated diagnosistic aid is added, and all participants were told that failures may occur in this system, but only half of the participants actually experienced them during the training. In the experimental trials, after nine correct diagnoses, the system gave a faulty one. For two subsequent faults, the system broke down entirely and no diagnostic support was available. Results:
- Correct diagnoses. During those trials where automated diagnoses were correct, the experience group took longer to identify the fault (time from fault indication to issuing correct repairs) than the information group. The experience group also sampled a higher percentage of the information that needed to be sampled for each fault (as learnt in the training phase), but neither group sampled all relevant information, i.e. all were complacent to some extent by this definition.
- False diagnosis. Only 5 out of 24 followed the false recommendation, i.e. showed a commission error. These were almost equally distributed across both groups; experience did not influence this. These five compared to the other nineteen participants however, took almost half as much time to identify failures in the correct-diagnoses trials, and sampled significantly less information (relevant and overall).
- No diagnoses. No significant effects were found.
The study suggested a new way to measure complacency in comparing actual behaviour to a normative model. All subjects showed complacency to some extent, extending the significance of complacency to decision support systems. Subjects in the information group were more complacent and took less time to verify diagnoses, hinting at a role of time pressure. Participants who committed a commission error also showed particularly high levels of complacency.
The impact of function allocation
Manzey, D., Reichenbach, J. & Onnasch, L. (2008). Performance consequences of automated aids in supervisory control: The impact of function allocation. Proceedings of the 52nd Meeting of the Human Factors and Ergonomics Society, New York, September 2008. Santa Monica: HFES, 297-301.
The authors investigate the effects of automation decision aids in terms of performance, automation bias, and deskilling, depending on level of automation.
In a simulated process of providing oxygen to astronauts, an automated system helped to diagnose errors. Information Analysis support provided just a diagnosis, Action Selection support provided additional action recommendations, and Action Implementation support also implemented these actions if the operator so requested. All were informed that the automation was imperfect and its diagnoses should be verified. Additionally, there was a full-manual control group. After training, the first experimental block was manual, two automated without faulty diagnoses, one automated with an additional misdiagnosis, and the last block was again manual. Effects are discussed on the following aspects.
Compared to a manual control group, support by an automated aid led to an increase in performance (faster and better), dependent on level of automation. Secondary task performance also showed improvement. However, up to half of the participants using the automated aid committed a commission error upon an automated misdiagnosis, regardless of level. A weak indication of (selective) deskilling has also been found.
The authors investigate the effects of automation decision aids in terms of performance, automation bias, and deskilling, depending on level of automation.
In a simulated process of providing oxygen to astronauts, an automated system helped to diagnose errors. Information Analysis support provided just a diagnosis, Action Selection support provided additional action recommendations, and Action Implementation support also implemented these actions if the operator so requested. All were informed that the automation was imperfect and its diagnoses should be verified. Additionally, there was a full-manual control group. After training, the first experimental block was manual, two automated without faulty diagnoses, one automated with an additional misdiagnosis, and the last block was again manual. Effects are discussed on the following aspects.
- Primary task performance. Fault identification time, percentage of correct diagnoses, and out-of-target-errors improved in automation blocks with significant difference between low plus middle versus high level of automation.
- Secondary task performance. Prospective memory task showed improvement in middle and high support groups. No differences were found in a secondary reaction time task.
- Automation bias. Up to half of the participants followed the misdiagnosis in block 4, but no differences were found for the different support types. A comparison of information sampling behaviour between those who did, and those who did not commit the error revealed no differences, suggesting the error was not due to a lack of verification, but due to a misperception or discounting of contradictory information. The effect being independent of level of automation suggests that medium levels of automation do not represent an efficient countermeasure.
- Return-to-manual performance. No effect was found on identification time or percentage of correct diagnoses. A slight effect was found in the highest-level automation group performing worse in terms of out-of-target-errors than the other two support types.
Compared to a manual control group, support by an automated aid led to an increase in performance (faster and better), dependent on level of automation. Secondary task performance also showed improvement. However, up to half of the participants using the automated aid committed a commission error upon an automated misdiagnosis, regardless of level. A weak indication of (selective) deskilling has also been found.
Automation Bias
Electronic Checklists
Mosier, K.L., Palmer, E.A. & Degani, A. (1992). Electronic Cheklists: Implications for Decision Making. Proceedings of the Human Factors Society 36th Annual Meeting, 7-11.
The improper use of checklists has been cited as a factor in several aircraft accidents. Solutions to checklist problems include the creation of electronic checklist systems. The authors compare the paper checklist to two types of electronic checklist systems.
The automatic-sensed checklist automatically checked all items that the system could sense were completed. The only manual control was to confirm the completed checklist at the end. The manual-sensed checklist required that the pilots manually touch the display for each item, which would only then be sensed and coloured accordingly (yellow for not completed, green for completed). Another independent variable was the instruction to perform immediate action items, i.e. the first few items of certain emergency checklists either from memory or by following these items from the checklist. Performing critical actions from memory allows a faster response, but also decreases the amount of thought that precedes the action; time savings gained may be overshadowed by an increase in errors.
The participating crews were brought in an ambiguous situation, needing to determine whether or not the #1 engine was on fire. Based on various cues, shutting down either engine could be "justified" -- #1 recovered from salient and serious warnings to stable, albeit somewhat reduced thrust, whereas #2 did not recover but did not have any salient initial warnings. The "engine fire" checklists recommended shutting down the #1 engine, although the best choice was to leave both running. Sample size was too small for statistical significance, but the following data is reported.
Crews that shut down #1 (bad) tended to be those with electronic checklists initiating the shutdown from memory. Crews that left both engines running (optimal) tended to be those whose shutdown procedures were less automated -- i.e. traditional paper checklists and/or not from memory.
No crew shut down #2. Apparently, the salience of the #1 cues overrode the less salient but more informative #2 cues.
The number of informational items discussed by crews decreased as the checklist became more automated.
Authors mention the importance of salience and the risk of perceptual tunneling when an item is too salient, especially when combined with stress, time pressure and information overload. Checklists can serve as a means to focus attention where it is needed. However, the checklist itself may then become the focus of attention and encourage crews not to conduct their own system checks, but rather rely on the checklist as primary system indicator (as with automatically sensed checks, or e.g. "already-checkd items must be okay").
The improper use of checklists has been cited as a factor in several aircraft accidents. Solutions to checklist problems include the creation of electronic checklist systems. The authors compare the paper checklist to two types of electronic checklist systems.
The automatic-sensed checklist automatically checked all items that the system could sense were completed. The only manual control was to confirm the completed checklist at the end. The manual-sensed checklist required that the pilots manually touch the display for each item, which would only then be sensed and coloured accordingly (yellow for not completed, green for completed). Another independent variable was the instruction to perform immediate action items, i.e. the first few items of certain emergency checklists either from memory or by following these items from the checklist. Performing critical actions from memory allows a faster response, but also decreases the amount of thought that precedes the action; time savings gained may be overshadowed by an increase in errors.
The participating crews were brought in an ambiguous situation, needing to determine whether or not the #1 engine was on fire. Based on various cues, shutting down either engine could be "justified" -- #1 recovered from salient and serious warnings to stable, albeit somewhat reduced thrust, whereas #2 did not recover but did not have any salient initial warnings. The "engine fire" checklists recommended shutting down the #1 engine, although the best choice was to leave both running. Sample size was too small for statistical significance, but the following data is reported.
Crews that shut down #1 (bad) tended to be those with electronic checklists initiating the shutdown from memory. Crews that left both engines running (optimal) tended to be those whose shutdown procedures were less automated -- i.e. traditional paper checklists and/or not from memory.
No crew shut down #2. Apparently, the salience of the #1 cues overrode the less salient but more informative #2 cues.
The number of informational items discussed by crews decreased as the checklist became more automated.
Authors mention the importance of salience and the risk of perceptual tunneling when an item is too salient, especially when combined with stress, time pressure and information overload. Checklists can serve as a means to focus attention where it is needed. However, the checklist itself may then become the focus of attention and encourage crews not to conduct their own system checks, but rather rely on the checklist as primary system indicator (as with automatically sensed checks, or e.g. "already-checkd items must be okay").
Accountability
Mosier, K.L., Skitkja, L.J., Heers, S. & Burdick, M. (1998). Automation Bias: Decision Making and Performance in High-Tech Cockpits. The International Journal of Aviation Psychology, 8 (1), 47-63.
Accountability is known to be able to mitigate classical decision-making biases and increase the tendency to use all available information for situation assessment. The authors investigated where other not these results would extend to experienced pilots using automation in the cockpit.
In the accountable condition, pilots were told they would be asked to justify their performance and strategies in the use of automation afterwards. The nonaccountable group was only told general information, and informed that due to a malfunction, no performance data could be recorded. The primary task was flying two legs, secondary was a tracking task. The primary task involved automated loading of new flight parameters given by ATC. The secondary task was fully automated in the first leg; in the second leg, it was manual above 5000 ft. Omission errors could be committed as primary task automation failed thrice, and secondary automation failed once during the first leg. Additionally, a false automated warning of an engine fire (contradicted by other indicators pointed out to the pilots during training) created the opportunity for a commission error. A checklist would recommend shutting down the engine.
5 out of 25 pilots made no errors. About half committed errors related to automation failures most critical to flight; none of them failed to notice the irrelevant secondary task automation failure. There was no difference between the two groups, but increased actual flight experience decreased the likelihood of catching the automation failures. Separating those who committed 2-3 errors from those who committed 0-1, showed that those who felt more accountable (regardless of experimental group) were less likely to make omission errors.
All pilots who received the engine warning ultimately shut down the engine, making a commission error. During the debriefing, 67% of them reported a phantom memory of at least one additional cue that was not actually present.
Because the results match those of a similar study earlier with non-experts, the authors conclude expertise does not protect against automation bias. In fact, expertise was related to a greater tendency to use automated cues. Externally imposed accountability was not found to be a factor, however, a subjectively reported higher internalised sense of accountability as gathered from the debriefing did seem relevant.
Accountability is known to be able to mitigate classical decision-making biases and increase the tendency to use all available information for situation assessment. The authors investigated where other not these results would extend to experienced pilots using automation in the cockpit.
In the accountable condition, pilots were told they would be asked to justify their performance and strategies in the use of automation afterwards. The nonaccountable group was only told general information, and informed that due to a malfunction, no performance data could be recorded. The primary task was flying two legs, secondary was a tracking task. The primary task involved automated loading of new flight parameters given by ATC. The secondary task was fully automated in the first leg; in the second leg, it was manual above 5000 ft. Omission errors could be committed as primary task automation failed thrice, and secondary automation failed once during the first leg. Additionally, a false automated warning of an engine fire (contradicted by other indicators pointed out to the pilots during training) created the opportunity for a commission error. A checklist would recommend shutting down the engine.
5 out of 25 pilots made no errors. About half committed errors related to automation failures most critical to flight; none of them failed to notice the irrelevant secondary task automation failure. There was no difference between the two groups, but increased actual flight experience decreased the likelihood of catching the automation failures. Separating those who committed 2-3 errors from those who committed 0-1, showed that those who felt more accountable (regardless of experimental group) were less likely to make omission errors.
All pilots who received the engine warning ultimately shut down the engine, making a commission error. During the debriefing, 67% of them reported a phantom memory of at least one additional cue that was not actually present.
Because the results match those of a similar study earlier with non-experts, the authors conclude expertise does not protect against automation bias. In fact, expertise was related to a greater tendency to use automated cues. Externally imposed accountability was not found to be a factor, however, a subjectively reported higher internalised sense of accountability as gathered from the debriefing did seem relevant.
Advantages of Teamwork
Mosier, K.L., Skitka, L.J., Dunbar, M. & McDonnell, L. (2001). Aircrews and Automation Bias: The Advantages of Teamwork? The International Journal of Aviation Psychology, 11 (1), 1-14.
From social psychology, a number of effects are known to be attributable to the presence of others.
The multilevel theory of team decision making says that several constructs influence decision-making accuracy in hierarchical teams.
The authors investigated the presence of a second crewmember on automation bias and associated errors. A previous study with students found that having a second crewmember, being trained to verify automated directives, and being visually prompted to verify automated directives did not have an effect on errors. Training participants on the phenomenon of automation bias however produced a significant reduction. The current study investigated whether or not these findings could be extended towards professional crews.
Independent variables: Crew size (alone or with another person), training (systems-only, additional emphasis on verification, additional explanation of biases and errors), display design (receiving a prompt to verify automated functioning or not).
Dependent variables: The number of omission and commission errors, as caused by failed automated loading of new flight directives and a false automated warning of an engine fire contradicted by other parameters (touching the warning screen brought up a checklist recommending engine shutdown).
No significant effect was found of crew size, training, or display design on omissions errors. 21% of automation (omission) errors were verbally acknowledged without corrective actions being taken (possibly due to a simulator effect, i.e. no real risk was present, or because crews are wary of correcting automation and instead question their own interpretation, or because they waited for a criticality expecting that otherwise, the error would correct itself). All solo-fliers and all but two crews (out of twenty) shut down the engine. In the debriefing, phantom memories were reported.
The presence of a second crewmember did not reduce automation bias and associated errors, nor did training or display prompts. The authors assume individual characteristics such as trust in automation, self-confidence, and internalised accountability play a more important role.
From social psychology, a number of effects are known to be attributable to the presence of others.
- Social facilitation is the tendency for people to do better on simple tasks when in the presence of others. Complex tasks however show the opposite effect. Drive theory explains this by a higher arousal in the presence of others, causing the individual to enact behaviours that form dominant responses. If the dominant response is correct, performance increases.
- Social loafing is the tendency of individuals to exert less effort when participating as a membe of a group than when alone, e.g. caused by deindividuation (dissociation from individual achievement and decrease of personal accountability).
The multilevel theory of team decision making says that several constructs influence decision-making accuracy in hierarchical teams.
- Team informity: The degree to which the team as a whole is aware of all the relevant cues or information.
- Staff validity: The degree to which each member of the team can produce valid judgements on the decision object.
- Hierarchical sensitivity: The degree to which the team leader effectively weights teammember judgements in arriving at the team's decision.
The authors investigated the presence of a second crewmember on automation bias and associated errors. A previous study with students found that having a second crewmember, being trained to verify automated directives, and being visually prompted to verify automated directives did not have an effect on errors. Training participants on the phenomenon of automation bias however produced a significant reduction. The current study investigated whether or not these findings could be extended towards professional crews.
Independent variables: Crew size (alone or with another person), training (systems-only, additional emphasis on verification, additional explanation of biases and errors), display design (receiving a prompt to verify automated functioning or not).
Dependent variables: The number of omission and commission errors, as caused by failed automated loading of new flight directives and a false automated warning of an engine fire contradicted by other parameters (touching the warning screen brought up a checklist recommending engine shutdown).
No significant effect was found of crew size, training, or display design on omissions errors. 21% of automation (omission) errors were verbally acknowledged without corrective actions being taken (possibly due to a simulator effect, i.e. no real risk was present, or because crews are wary of correcting automation and instead question their own interpretation, or because they waited for a criticality expecting that otherwise, the error would correct itself). All solo-fliers and all but two crews (out of twenty) shut down the engine. In the debriefing, phantom memories were reported.
The presence of a second crewmember did not reduce automation bias and associated errors, nor did training or display prompts. The authors assume individual characteristics such as trust in automation, self-confidence, and internalised accountability play a more important role.
Automation Bias in Mammography
Alberdi, E., Povyakalo, A., Strigini, L. & Ayton, P. (2004). Effects of Incorrect Computer-aided Detection (CAD) Output on Human Decision-making in Mammography. Academic RAdiology, 11, 909-919.
CAD searches for typical patterns and highlights these to support human decision making. Sensitivity is the amount of true positives over the amount of actual positives (true positive + false negative); specificity is the amount of true negatives over the amount of actual negatives (true negative + false positive).
The authors investigated the effects of incorrect CAD output on the reliability of the decisions of human users. Three studies are described.
In the base study, groups of more and less qualified practitioners indicated on mammograms which areas were indicative of cancer, and whether or not the patient should (probably) return. All readers reviewed each case twice, once with, once without CAD, with a week in between. In the CAD condition they were instructed to first look at the films themselves, and were told about possible CAD errors.
The goal of the first follow-up study was to further investigate the human response to CAD's false negatives (either failing to place a prompt or by placing prompts away from the actual cancer area). Only 16 out of 180 cases of the base study were false negatives, so a new data set was compiled. There was no no-CAD condition. The second follow-up study only had a no-CAD condition for comparison.
The base study turned out that in conditions with CAD, readers were more confident in their decision ("no recall" instead of "discuss but probably no recall") than for the same cases without CAD. The reader sensitivity in this study was 76% in the CAD condition. In study 1, however, this was only 52%. Where CAD incorrectly marked, or didn't mark, cancer cases, the percentage of correct decisions was low; it was high in other cases. In study 2, sensitivity was still low, but significant differences were found between study 1 and 2 in percentage of correct decisions in the unmarked and incorrectly marked cases, with worse performance in the study 1 (CAD condition).
Analyses suggest that the output of the CAD tool, in particular the absense of prompts, might have been used by the readers as reassurance for "no recall" decisions for no-cancer cases. One could argue that the readers tended to assume that the absence of prompting was a strong indication for no-cancer, paying less attention to these cases (error of omission, reliance).
CAD searches for typical patterns and highlights these to support human decision making. Sensitivity is the amount of true positives over the amount of actual positives (true positive + false negative); specificity is the amount of true negatives over the amount of actual negatives (true negative + false positive).
The authors investigated the effects of incorrect CAD output on the reliability of the decisions of human users. Three studies are described.
In the base study, groups of more and less qualified practitioners indicated on mammograms which areas were indicative of cancer, and whether or not the patient should (probably) return. All readers reviewed each case twice, once with, once without CAD, with a week in between. In the CAD condition they were instructed to first look at the films themselves, and were told about possible CAD errors.
The goal of the first follow-up study was to further investigate the human response to CAD's false negatives (either failing to place a prompt or by placing prompts away from the actual cancer area). Only 16 out of 180 cases of the base study were false negatives, so a new data set was compiled. There was no no-CAD condition. The second follow-up study only had a no-CAD condition for comparison.
The base study turned out that in conditions with CAD, readers were more confident in their decision ("no recall" instead of "discuss but probably no recall") than for the same cases without CAD. The reader sensitivity in this study was 76% in the CAD condition. In study 1, however, this was only 52%. Where CAD incorrectly marked, or didn't mark, cancer cases, the percentage of correct decisions was low; it was high in other cases. In study 2, sensitivity was still low, but significant differences were found between study 1 and 2 in percentage of correct decisions in the unmarked and incorrectly marked cases, with worse performance in the study 1 (CAD condition).
Analyses suggest that the output of the CAD tool, in particular the absense of prompts, might have been used by the readers as reassurance for "no recall" decisions for no-cancer cases. One could argue that the readers tended to assume that the absence of prompting was a strong indication for no-cancer, paying less attention to these cases (error of omission, reliance).
Automation Bias and Reader Effectiveness in Mammography
Alberdi, E., Povyakalo, A.A., Strigini, L., Ayton, P. & Given-Wilson, R. (2008). CAD in mammography: lesion-level vs. case-level analysis of the effects of prompts on human decisions. International Journal of Computer Assisted Radiology and Surgery, 3 (1-2), 115-122.
Previous studies have used data at the level of cases (e.g. recall/no recall). The current study used data at the level of mammographic features, allowing them to e.g. identify recalls based on mammographic features that CAD had not prompted. Additionally, differences between readers are investigated, as the absense of significant effects in other studies may be caused by a balancing effect.
Data used was, for each mammogram, those areas known to be cancer regions, marked by CAD, and marked by readers. Additionally the readers indicated each type of abnormality they spotted, their degree of suspicion for each mark, and their recall/no recall decision. Mammographs were used of 45 "non-obvious" cancer cases. The following analyses were conducted.
Previous studies have used data at the level of cases (e.g. recall/no recall). The current study used data at the level of mammographic features, allowing them to e.g. identify recalls based on mammographic features that CAD had not prompted. Additionally, differences between readers are investigated, as the absense of significant effects in other studies may be caused by a balancing effect.
Data used was, for each mammogram, those areas known to be cancer regions, marked by CAD, and marked by readers. Additionally the readers indicated each type of abnormality they spotted, their degree of suspicion for each mark, and their recall/no recall decision. Mammographs were used of 45 "non-obvious" cancer cases. The following analyses were conducted.
- Recalls for non-cancer areas. False-target recalls are recalls based on erroneous features, as opposed to true-target recalls. 13,5% of recall decisions were false-target recalls in both CAD and no-CAD conditions, with some overlap of cases between conditions.
- Effects of prompts on feature classification. The lack of a correct CAD prompt significantly decreased the probability of a reader marking a cancer area at all, and the probability of a reader indicating the area as suspicious (>3). The presence of a prompt had significant positive effects on both measures.
- Readers' reactions to prompts. Prompts increased the probability of a reader marking that feature; false positive prompts even more so than true positive prompts. The same effects are found for the probability of marking the feature as suspicious.
- Predictors of reactions to prompts. Analysis suggests that a CAD prompt significantly reduces, by up to 10%, the probability of false negative error for the less effective readers on moderately difficult-to-detect features. For the 10-20% most effective readers, there is a significant negative estimated effect, i.e. an increase in the probability of false negative errors on features of moderate difficulty.
Alarms
Why Better Operators Receive Worse Warnings
Meyer, J. & Bitan, Y. (2002). Why Better Operators Receive Worse Warnings. Human Factors, 44 (3), 343-353.
The authors suggest that the occurence of warnings in complex systems often depends on the operators' characteristics, and that the diagnostic value of a warning decreases for better operators.
An informative way to evaluate a system is in terms of positive predictive value and negative predictive value (percentage of true positives/negatives out of all indicated positives/negatives). Expert operators are likely to decrease the probability of a failure, necessarily also decreasing the PPV and increasing the NPV. In extreme cases, all failures are prevented by the operator, and the only alarms given are false positives.
This was experimentally tested. Participants had to monitor three stations reflecting a numerical value that diminished over time at different rates of change. To see the value of a station, it had to be inspected. Only one station could be inspected at a time. Upon inspection, the value could be reset. Inspection cost 5 points, intervention 20. Participants lost points for negative stations and gained points for positive stations. Optimal scheduling required intervention every 22, 33 and 66 seconds for the three stations (order randomised). A warning system indicated whether or not a station value was positive or negative, with some probability for false alarms and misses. The warning systems differed across conditions in their sensitivity and response criteria.
PPV was higher for more sensitive and more cautious warning systems, as is to be expected. Additionally, PPV decreased over subsequent trials purely as the result of an improvement in operator performance, reducing the proportion of periods with negative values. Similarly, NPV increased over trials.
The authors suggest that the occurence of warnings in complex systems often depends on the operators' characteristics, and that the diagnostic value of a warning decreases for better operators.
An informative way to evaluate a system is in terms of positive predictive value and negative predictive value (percentage of true positives/negatives out of all indicated positives/negatives). Expert operators are likely to decrease the probability of a failure, necessarily also decreasing the PPV and increasing the NPV. In extreme cases, all failures are prevented by the operator, and the only alarms given are false positives.
This was experimentally tested. Participants had to monitor three stations reflecting a numerical value that diminished over time at different rates of change. To see the value of a station, it had to be inspected. Only one station could be inspected at a time. Upon inspection, the value could be reset. Inspection cost 5 points, intervention 20. Participants lost points for negative stations and gained points for positive stations. Optimal scheduling required intervention every 22, 33 and 66 seconds for the three stations (order randomised). A warning system indicated whether or not a station value was positive or negative, with some probability for false alarms and misses. The warning systems differed across conditions in their sensitivity and response criteria.
PPV was higher for more sensitive and more cautious warning systems, as is to be expected. Additionally, PPV decreased over subsequent trials purely as the result of an improvement in operator performance, reducing the proportion of periods with negative values. Similarly, NPV increased over trials.
On the Independence of Compliance and Reliance
Dixon, S.R., Wickens, C.D. & McCarley, J.S. (2007). On the Independence of Compliance and Reliance: Are Automation False Alarms Worse Than Misses? Human Factors, 49 (4), 564-572.
Previously, it had been implied that compliance and reliance are separate, possibly even independent constructs -- that an increase in false alarms should affect only compliance and an increase in misses should affect only reliance.
Participants performed two tasks concurrently: A continuous compensatory tracking task, and a cognitively demanding systems monitoring tasks. The second task was performed either unaided, with perfectly reliable, FA prone, or miss prone automation. The authors hyposesised that
Previously, it had been implied that compliance and reliance are separate, possibly even independent constructs -- that an increase in false alarms should affect only compliance and an increase in misses should affect only reliance.
Participants performed two tasks concurrently: A continuous compensatory tracking task, and a cognitively demanding systems monitoring tasks. The second task was performed either unaided, with perfectly reliable, FA prone, or miss prone automation. The authors hyposesised that
- perfect automation would benefit both tasks;
- miss-prone automation would reduce reliance, shift attention away from the tracking task to catch misses, and therefore harm the tracking task;
- an increase in misses should not affect compliance measures (speed of response to an alert);
- FA-prone automation should reduce compliance and therefore harm the system monitoring task;
- FAs should also reduce reliance and therefore harm the tracking task.